

GraphQL es un lenguaje de consulta (query language) que ha sido visto como una mejora en eficiencia, flexibilidad y potencial sobre formas previas de implementar una API.
API significa (en inglés) Application Programming Interface (interfaz de programación de aplicación). Es la forma que diferentes aplicaciones pueden compartir datos, al exponer una interfaz pública. Usualmente, esta interfaz está determinada por una URL y una serie de parámetros que permiten consultar o enviar datos.
GraphQL es la especificación de un lenguaje de consulta que se enfoca en la forma en que se obtienen los datos. Fue originalmente desarrollado y presentado por Facebook, pero actualmente el estándar es mantenido como open source por una creciente comunidad.
Puedes ver la Keynote en donde se presentó la especificación en el siguiente video.
Al ser una especificación, GraphQL no está atado a ningún lenguaje o base de datos en particular, si no más bien cada lenguaje puede implementar su propia solución para soportar la especificación. La gran mayoría de las implementaciones son utilizadas sobre HTTP, aquí la principal idea es enviar POST una consulta query a una URL en particular.

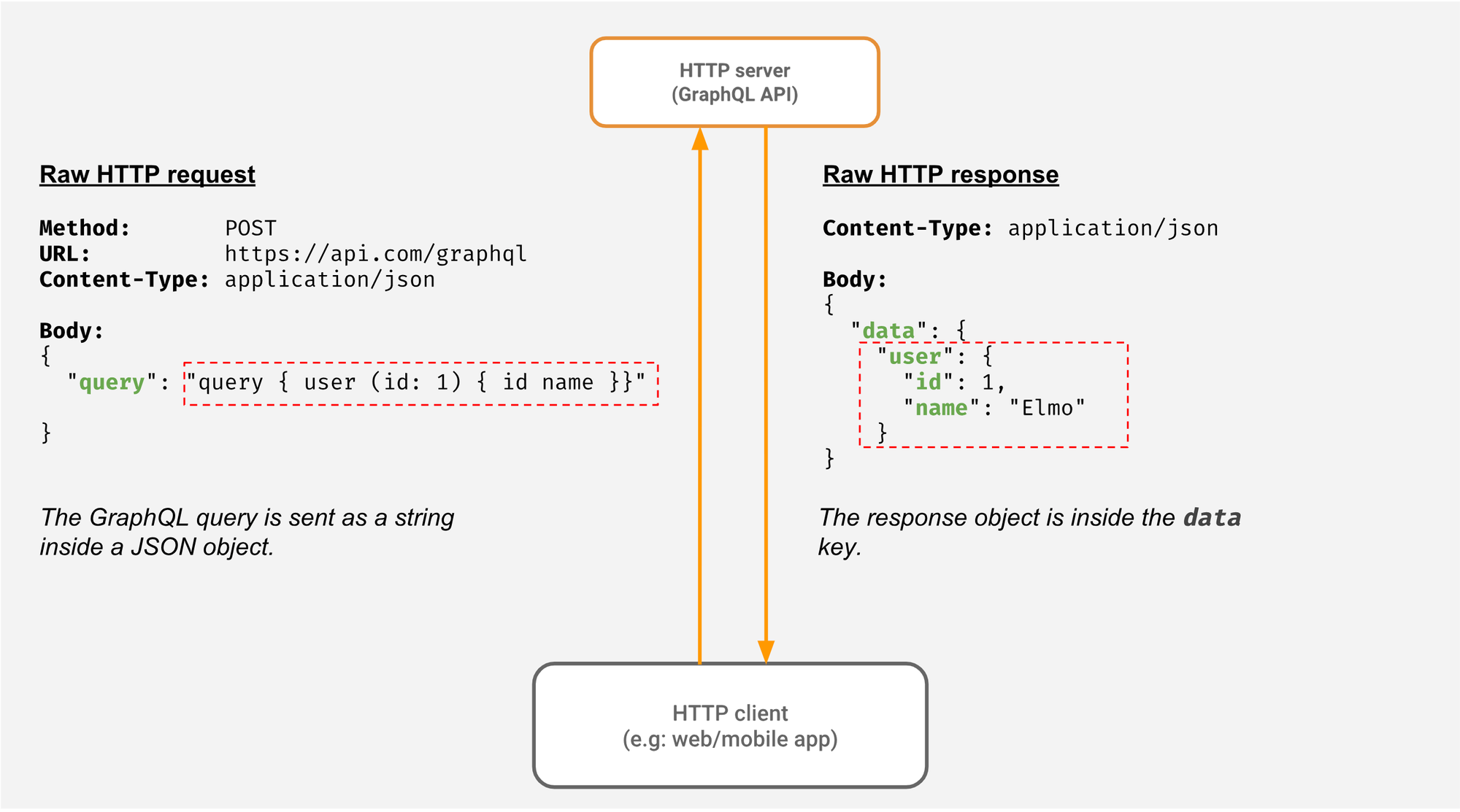
Diagrama obtenido de la documentación de Hasura
En este diagrama puedes encontrar una descripción de la comunicación entre un cliente y servidor de GraphQL.
- El cliente crea una consulta GraphQL (
query) que describe la información que se quiere obtener. - El servidor expone una sola URL
endpoint(usualmente/graphql) - El cliente ejecuta una llamada
POSTal endpoint provisto por el servidor enviando la consulta definida como un string JSON. - El servidor recibe la consulta, la procesa y responde con datos en formato JSON que tiene la misma estructura que la consulta recibida.
GraphQL permite el uso de "declarative data fetching" (obtención de datos declarativa), es decir, el cliente es quien define y específica que datos necesita exactamente.
A modo de comparación, en el caso de una API tipo REST, el servidor expone múltiples endpoint para cada uno de los recursos expuestos y es el servidor quien define que datos se retornan en cada URL.
Esta idea de permitir al cliente definir los datos requeridos permite evitar algunos problemas de "sobre consulta" existentes en la arquitectura REST en donde muchas veces un endpoint retorna una excesiva cantidad de datos, creando dificultades en asegurar que el cliente está recibiendo el set de datos correcto.
Otro problema que GraphQL intenta resolver es el consultar diferentes recursos o entidades relacionadas, en el caso de REST esto implica consultar diferentes endpoints, en GraphQL todas las consultas son enviadas a un mismo endpoint provisto por el servidor.
Características
Hay una serie de características claves en el diseño de GraphQL: Declarativo, Jerárquico, Introspectivo y fuertemente tipado.
Declarativo
Las consultas en GraphQL son declarativas, es decir, el cliente declara exactamente que campos o atributos necesita. La respuesta recibida sólo incluirá dichas propiedades.
El código anterior muestra una consulta que permite obtener un user identificado por el id "1". Esta consulta solicita los campos name, address e email.
La posible respuesta a esta consulta será un objeto en formato JSON cuyo atributo data será un objeto que contiene los campos solicitados.
Jerárquica
Las consultas en GraphQL son jerárquicas. Los datos retornados siguen la misma forma o definición de la consulta.
La consulta anterior ha sido extendidad para incluir el campo networks que a su vez solicita los campos name y url.
La respuesta ahora incluye un arreglo con todos los valores asociados a la propiedad networks de este user en particular. GraphQL no tiene opinión ni fuerza una forma de almacenamiento de datos en particular, por lo que es incluso posible que users y networks estén almacenados en distintas bases de datos. Si esto fuese así, es el servidor que implementa la especificación GraphQL y expone el endpoint quien debe ocuparse de recolectar los datos (implementación de resolvers).
Introspectivo o autodocumentado
La Introspección es una característica que permite que clientes puedan obtener el esquema que da forma a los datos utilizados por ese endpoint GraphQL. Esto permite la creación de herramientas como GraphQL, un playground para el servidor que permite ejecutar consultas, pero por sobre todo acceder a la documentación existente.
Por medio de esta característica es posible conocer que otras propiedades pueden ser consultadas para el campo networks sin la necesidad de mirar el código del servidor.
Esta consulta retornara la descripción del esquema, algo similar a:
Fuertemente Tipado
La especificación describe un sistema de tipos lo que permite definir las capacidades que cada valor o campo tendrá dentro del servidor GraphQL.
Los tipos utilizados dentro del esquema son muy similares a los tipos encontrados en Typescript y otros lenguajes, incluyendo primitivas como String,Boolean, Int y tipos más avanzados.
Este ejemplo define un tipo objeto llamado Network, que se compone de dos campos requeridos name y url, ambos del tipo String y un campo opcional priority de tipo Int.
El esquema de GraphQL es definido utilizando el sistema de tipos, lo que permite al servidor determinar si una consulta es o no válida antes de intentar ejecutarla.
Este sistema de tipos permite asegurar que las consultas son sintéticamente correctas, evitando así ambigüedades y errores.
Arquitectura
Las implementaciones de GraphQL constan de dos partes esenciales:
- Un cliente que es ejecutado en tu aplicación web o móvil
- Un servidor, que expone un endpoint, recibe las consultas y realiza el mapeo de dichas consultas (
query) con su correspondiente set de datos (resolvers).
Servidor
Una API GraphQL es definida usualmente con un solo endpoint, por lo general una URL que termina en /graphql. Por medio de esta URL es posible acceder a todas las consultas y mutaciones ofrecidas por el servidor, incluyendo la introspección o soluciones como GraphQL (si es ofrecida).
Dado que GraphQL es una especificación totalmente agnóstica de la tecnología subyacente o de el "medio de transporte" utilizado, el servidor puede ser desarrollado con tu stack preferido o incluso utilizando protocolos de comunicación diferentes como RPC, sin embargo, lo más común es que el endpoit sea servido mediante HTTP.
Existen muchas implementaciones de servidores GraphQL, en el mundo de Node.js puedes encontrar varias alternativas como por ejemplo:
- graphql/graphql-js La implementación de referencia para la especificación.
- Apollo Server Una implementación en TypeScript soportada por la comunidad open source que puede ser utilizada sobre frameworks como Express, Koa, Hapi o de forma aislada.
- Express GraphQL Una implementación base sobre Express.
Puedes encontrar más implementaciones en este sitio web
El servidor se encargará de escuchar las peticiones realizadas por los clientes y convertir o resolver dichas consultas comunicándose con la capa de datos correspondiente.
GraphQL es completamente agnóstico y sin opinión sobre que base de datos debes utilizar, incluso es posible que puedas utilizar múltiples soluciones para almacenar y consultar tus datos, permitiéndote realizar agregación de datos que luego serán provistos como respuesta a la consulta por medio del único endpoint.
Lo importante es definir correctamente el esquema que declarará cuál es la API de los datos disponibles a ser consultados.
Cliente
Las consultas (y mutaciones) realizadas hacia el servidor GraphQL son llamadas documents que tienen cierto formato definido por la especificación.
Existen varios clientes que permiten realizar algunas operaciones avanzadas como manejo de Caché, reiteración en caso de error, etc. También puedes hacerlo con "vainilla" JavaScript, ya que estos documentos no son más que un string JSON.
Esta consulta puede ser fácilmente implementada utilizando fetch.
Algunos clientes javascript que puedes encontrar:
- Apollo Client: Integra mecanismos de caching, mutaciones optimisticas, etc. Compatible con React, Angular y más.
- AWS Amplify: Client para trabajar con servicios en la nube.
- Graphql Request: Simple y flexible client. Básicamente, es un "wrapper" sobre
fetch. - Relay: Creado por Facebook como solución para crear aplicaciones complejas con React.
Encuentra más soluciones en este enlace
¿Por que usar Graphql sobre Rest?
Esta pregunta tipo "versus" es muy común, pero era en un punto. GraphQL y REST no son conceptos intercambiables.
Sí, es cierto que ambos conceptos buscan resolver problemas similares, pero son ideas diferentes.
REST son las siglas de Representational State Transfer. Es una arquitectura de software que permite definir como se comparten datos entre sistemas. Una API REST es una API que implementa los principios y restricciones definidas por REST, tales como: No maneja estado, es "cacheable", separa las tareas o intereses del cliente y el servidor, mantiene una interfaz uniforme.
GraphQL, es la especificación de un lenguaje de consulta.
Como todo en el mundo del desarrollo web, ambas ideas, conceptos e implementaciones tiene puntos a favor y en contra y ambos tienen usos en el día de hoy.
Quizá la principal ventaja de GraphQL sobre REST es que mantiene un solo punto de entrada, permitiendo (o forzando) agregar o recolectar la información necesaria - que incluso podría provenir de varias API REST - para ser servida tal y como el cliente la solicitó.
GraphQL es un restaurante a la carta. REST es un comedor en donde el chef define que comerás.
Esto, resuelve el problema de over-fetching y under-fetching.
Además, con GraphQL puedes:
- Prevenir el uso de múltiples llamadas a la API: Con REST, si necesitas más datos debes realizar más llamadas a las diferentes URL de cada recurso, con GraphQL puedes agregar las consultas y ejecutar una sola llamada.
- Mejora la comunicación entre desarrolladores de la API y el Cliente.
- Documentación: Dado que GraphQL implementa un esquema y además debe ser introspectivo, la generación automática de documentación viene de forma gratuita.
¿Cómo comenzar con GraphQL?
Puedes desarrollar tu capa de abstracción con GraphQL tanto para consumir una API GraphQL (cliente) o creando tu propia API (server).
En este breve ejemplo crearás:
- Un servidor que ofrece una API GraphQL para consultar nombres de usuarios y sus artículos publicados.
- Un cliente en React que consulta la API
Puedes encontrar el código fuente de este ejemplo en este repositorio.
Servidor
Comencemos por el servidor, primero, crea un directorio y dentro de el dos directorios más
Ahora dentro del servidor, crearemos un nuevo proyecto, instalar las dependencias y escribir el código.
Ahora actualiza el archivo package.json y agrega:
Ahora es tiempo de constuir el schema para luego crear los resolvers para cada query.
El esquema lo crearemos directamente escribiendo graphql, para eso: crea un directorio llamado graphql y dentro de el un archivo index.graphql
En este archivo defines los tipos de tus datos o entidades, además de cuáles serán los nombres para las consultas y los datos retornados.
Aquí has creado dos tipos: Article y User. Cada uno define sus propios atributos indicando cuáles son requeridos al utilizar el símbolo !.
Además, se definen las consultas disponibles dentro del tipo objeto Query. En este caso, tu API podrás permitir consultas para users, user y articles.
Ahora, definiremos los resolvers. Dado que este un demo pequeño, puedes escribir los resolvers directamente en el archivo principal.
Crea un archivo llamado server.js y dentro de él crea un objeto llamado resolvers.
Este objeto tiene la misma estructura que el tipo Query definido anteriormente.
Puedes asumir que los datos provienen de alguna API externa o base de datos, para este caso usaremos fakerjs para crear datos de prueba.
Crea un archivo llamado data.js esta será la forma de emular una API o DB.
Este archivo simplemente crea un arreglo de usuarios y otro de artículos con datos ficticios.
De vuelta al archivo server.js
Es hora de importar los datos ficticios y definir los resolvers.
Importante notar que la función user recibe dos argumentos. Estos argumentos están definidos por graphql desde la definición de la query, ya que esta query contiene argumentos.
Ahora, utilizando una de las dependencias instaladas, definires el schema e iniciaremos el servidor (mismo archivo)
Con esto en su lugar, ya puedes iniciar tu servidor con
y visitar
en donde verás el client gráfico y documentación.

Cliente
Para el cliente, creamos una pequeña app React utilizando vitejs.
Para eso, dentro de la raíz de tu proyecto ejecuta
Sigue las instrucciones y seleccion react.
Ahora, agregarás algunas dependencias para poder comunicarte con tu servidor graphql.
Ahora ya puedes editar el código de esta pequeña app. Abre src/App.jsx. Puedes eliminar su contenido.
Dado que este es un pequeño demo, definiremos los componentes directamente en este archivo.
Primero, definir como se consultarán los datos.
Con este trozo de código (que nada tiene que ver con React y puede ser utilizado en cualquier framework). Has definido:
- Dos consultas utilizando
gqlpara poder escribir directamente en graphql - Un cliente utilizando
GraphqlClient - Dos funciones asícronas que ejecutan la llamada al servidor y retornan los datos correspondientes.
Ahora, creemos un componente para desplegar los usuarios.
Este componente es una simple tabla que despliega los usuarios obtenidos utilizando requestUsers.
Usando useEffect ejecuta la llamada al servidor graphql al momento de renderizar el componente y almacena esos datos en el estado utilizando useState.
También puedes consultar datos reaccionando a un evento de usuario como en este componente para desplegar artículos.
Muy similar al anterior componente pero esta vez se renderiza un botón que al ser clickeado ejecuta una función para obtener los datos.
Finalmente, renderiza los componentes
Puedes ver todo en funcionamiento al abrir dos terminales y en una ejecutar el servidor y en otra el cliente
Conclusión
GraphQL es la especificación de un lenguaje de consulta y un "runtime" mantenida por la comunidad open-source. Busca resolver varios problemas encontrados en las ya tradicionales implementaciones de REST como over/under fetching, uso ineficiente de las llamadas de red, etc.
Sin embargo GraphQL no es un reemplazo directo de REST dado que son conceptos diferentes e incluso pueden convivir en una misma implementación.